


Enforce Workload Automation continuous operation by activating Automatic failover feature and an HTTP load balancer

How important is that your Workload Automation environment is healthy, up and running, and there are no workload stops or delays? What happens if your Master Domain Manager becomes unavailable or it is affected by downtime? What manual recovery solution you must do when it happens? How can I distribute simultaneously requests to several application servers in my configurations if my primary server is drowning? How can I hourly monitor the workload automation environment healthy in an easy way? How can I have an alerting mechanism?
The answer is: Workload Automation 9.5 FP2 with Automatic failover feature enabled, combined with NGINX load balancer!
Let start to introduce the components participating to the solution:
= Workload Automation 9.5 FP2 introduces the Workload Automatic failover feature = When the active master domain manager becomes unavailable, it suddenly enables an automatic switchover to a backup engine and event processor server. It ensures continuous operation by configuring one or more backup engines so that when a backup detects that the active master becomes unavailable, it triggers a long-term switchmgr operation to itself. You can define potential backups in a list by adding preferential backups at the top of the list. The backup engines monitor the behaviour of the master domain manager to detect anomalous behaviour.
= NGINX load balancer = Load balancing across multiple application instances is a commonly used technique for optimizing resource utilization, maximizing throughput, reducing latency, and ensuring fault-tolerant configurations. It is possible to use NGINX as a very efficient HTTP load balancer to distribute traffic to several application servers and to improve performance, scalability and reliability of web applications. Nginx acts as a single–entry point to a distributed web application working on multiple separate servers.
Let continue analyzing our use case solution:
We experiment the solution by defining and using this environment during the formal test phase for 9.5 FP2 project.
The NGINX load balancer comes handy in to have a fully high available Workload Automation (WA) environment. For the Dynamic Workload Console (DWC), you just need to ensure that it is connected to an external DB and link it to a load balancer to dispatch multiple requests coming from the same user session of one DWC instance. We used the DWC-NGINX configuration as the only access point for all the DWC instances present in our test environment.
After configuring DWC– NGINX, we configured a new server connection on it, in order to have already managed the automatic switching among masters when it occurs. The best way to do this is to define a load balancer (named ENGINE-NGINX in Figure 3) in front of your master machines and behind the DWC-NGINX machines, and specifying the public hostname of the <DWC-NGINX> load balancer as the endpoint of your server connections in the DWC or in your client apps. In this way, you have only a hostname that maps the current active master, so you do not take care about current master management.
Another feature introduced by 9.5 fix pack 2 allows the backup workstations to manage a subset of HTTP requests (For example: requests on the Workload Service Assurance) coming from the other workstations in the environment. Backup workstation receives all HTTP requests from the active master, manages the possible ones and re-sends the requests it cannot manage to the active master itself.
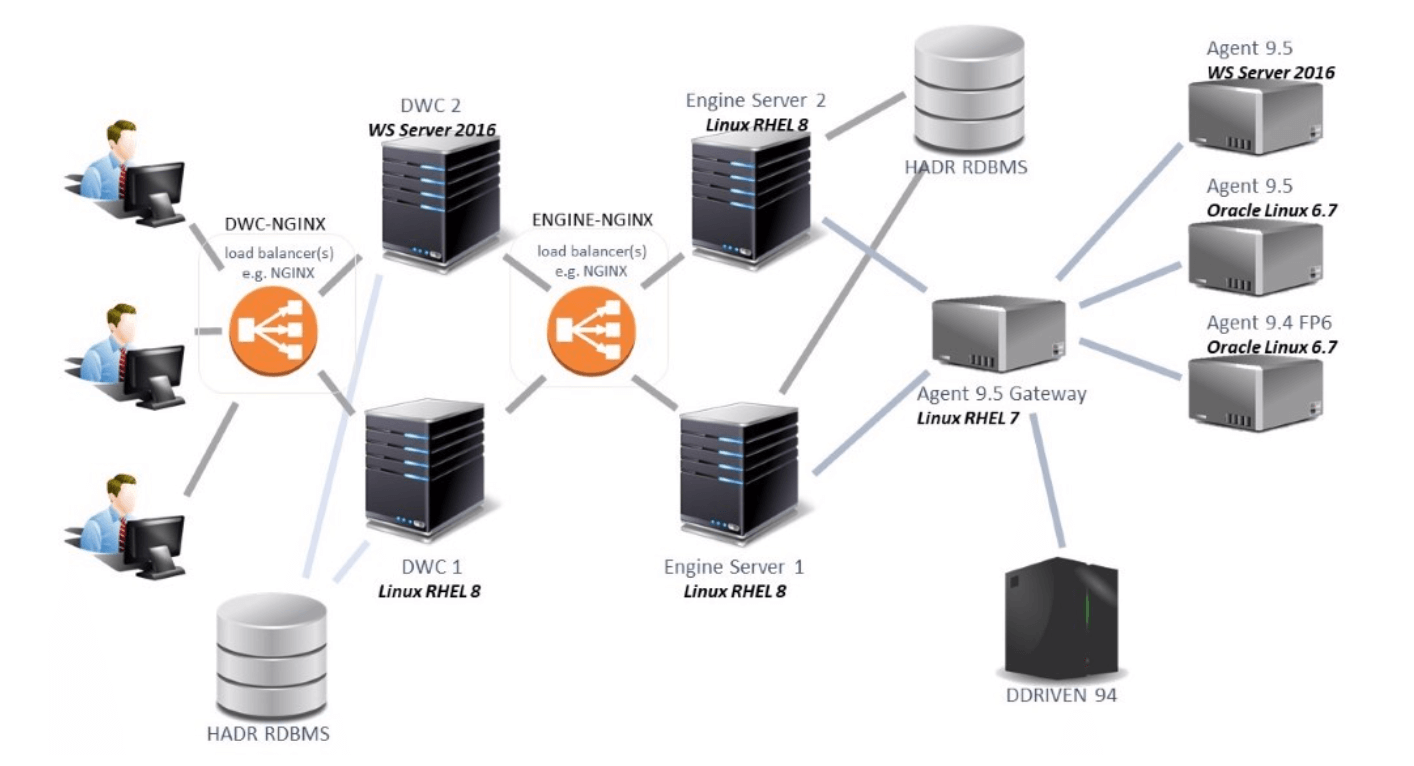
Figure 1: Automatic Failover SVT environment
In Figure 1, the load balancers are depicted as two distinct ones, the most general case possible, but for the SVT environment, we have used a single component for balancing the request to the DWC machines and to the server machines.
Let introduce the configuration we used to orchestrate the 3 components in the solution:
WA automatic failover configuration:
We used the default configuration of Automatic failover installed with a new WA server, defined by the following WA global options.
enAutomaticFailover = yes
enAutomaticFailoverActions= yes
workstationEventMgrListInAutomaticFailover (empty)
workstationMasterListInAutomaticFailover (empty)
For more info about global options meaning, see the official documentation.
Let’s go in drill down into the workstationMasterListInAutomaticFailover global option. After the first test cycle, we changed its default value. We defined multiple backup masters in the list and we define the order of which of them should be considered as the first candidate master for the switching operation:
workstationMasterListInAutomaticFailover = BKM1, BKM2, MDM
This parameter contains an ordered list of workstations separated with comma that acts as backups for the main processor. If a workstation is not included in the list, it will never be considered as a backup. The switch is first attempted by the first workstation in the list, and otherwise an attempt is made from the second row, and so on. These switches take place after a 5-minute threshold period, so if the first backup is not eligible, it has to spend 5 more minutes before the switch takes place on the next backup in the list. This offers an additional layer of control over backups. because it allows you to define a list of eligible workstations. if no workstation is specified in this list, all managers of the backup master domain in the domain are considered eligible backups.
NGINX load balancer configuration:
Engine:
For engine server machines, we used the round-robin load balancing mechanisms. Going down the list of servers in the group, the round‑robin load balancer forwards a client request to each server in turn. On round-robin load balancing each request can be potentially distributed to a different server. There is no guarantee that the same client will be always directed to the same server. The main benefit of round‑robin load balancing is that it is extremely simple to implement. We used a weighted round-robin: a weight is assigned to each server, in our case we have balanced the load equally but higher is the weight, the larger the proportion of client requests the server can be receives.
DWC:
For DWC server machines, we used ip-hash configuration. By defining ip-hash configuration, the client’s IP address of coming request is used as a hashing key to determine what server in a server group should be selected for the client’s requests. This method ensures that the requests from the same client will always be directed to the same server except when this server is unavailable.
We applied the following complete NGINX configuration for the DWC and Engine component respectively:
upstream wa_console { ##DWC configuration
ip_hash;
server DWC_SERVER1 max_fails=3 fail_timeout=300s;
server DWC_SERVER2 max_fails=3 fail_timeout=300s;
keepalive 32;
}
server{
listen 443 ssl;
ssl_certificate /etc/nginx/certs/nginx.crt;
ssl_certificate_key /etc/nginx/certs/nginxkey.key;
ssl_trusted_certificate /etc/nginx/certs/ca-certs.crt;
location /
{
proxy_pass https://wa_console;
proxy_cache off;
proxy_set_header Host $host;
proxy_set_header Forwarded ” $proxy_add_x_forwarded_for;proto=$scheme”;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Port 443;
}
}
upstream wa_server_backend_https { ##SERVER configuration
server ENGINE_SERVER1 weight=1;
server ENGINE_SERVER2 weight=1
}
server{
listen 9443 ssl;
ssl_certificate /etc/nginx/certs/nginx.crt;
ssl_certificate_key /etc/nginx/certs/nginxkey.key;
ssl_trusted_certificate /etc/nginx/certs/ca-certs.crt;
location /
{
proxy_pass https://wa_server_backend_https;
proxy_cache off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Connection “close”;
}
}
Let describe how we performed Automatic failover and NGINX test scenarios:
We focused on various verification test scenarios in order to verify the effectiveness of the load balancer dispatching for active master and eligible backups and the automatic failover triggering in case of active master triggered failure by a sort of chaos engineering test procedure.
WA SERVER
= Failure of the main processes of Workload Automation (Batchman, Mailman, Jobman) =
We randomly introduced engine server failure of the main processes of Workload Automation in the active master workstation.
One of the scenarios that triggers automatic failover is the failure of one or more Workload Automation main processes: Batchman, Mailman and Jobman.
Each main process, as default after abnormal stopping, is automatically restarted. In order to simulate an abnormal failure in the active master workstation, you need to kill one or more of the main processes, at least three consecutive times, the process is not restarted. So after 5 minutes, the automatic failover process switches the master role to first healthy backup workstation available.
NOTE:
Keep in mind that we do not have the automatic failover if Netman process is killed or stopped.
= Stop or failure of the Liberty Application Server =
You can trigger the automatic failover process if you kill the Liberty Application Server in the active master workstation for at least 5 minutes. We performed both scenarios, and if the Liberty process is not able for 5 minutes to restart, first available and eligible backup workstation becomes new master workstation. If the Liberty Application Server is restarted before 5 minutes in the active master workstation (it normally happens because the appserverman process restart it!), the automatic failover action is not performed because the master is available to execute the processes.
= Mailbox corruption =
We tested also the scenario where a Mailbox.msg file corruption happens on the active master workstation and caused the automatic failover switching process to another eligible and healthy backup workstation. We simulated a corruption of the msg files or substituted the original msg file with an old version corrupted file to cause the automatic switching. Thank God, we had lot of problem to simulate the corruption!
DWC
We focused on the following test cases in order to verify the correct activity of the load balancer for both DWC instances:
= Multiple access to DWC-NGINX use case =
We tried multiple simultaneously user accesses to the DWC-NGINX entry point from different machines while multiple users are performing several tasks on plan, database, reporting and custom dashboard monitoring. Each user was able to perform its tasks without interruption or latency, as a user logged in to a not balanced DWC instance. The workload tasks coming from multiple accesses have been correctly dispatched between the two DWC-SERVER, avoiding to congest only one instance with multiple coming requests.
= Redirecting traffic to the active DWC if one of this is meting problem =
We tried to randomly stop one of the DWC instance, in order to verify that the DWC-NGINX correctly redirect traffic to the instance that is active, allowing the user to continue work on the DWC without big mess. The only disruption is for users that had a session opened in the stopped DWC instance, they need to re-login to have a new session on the only available DWC instance.
Conclusion
Don’t be stopped by unexpected failures anymore, with Workload Automation 9.5 Fix Pack 2 you can rest easy during the night, let go to a happy hour or to the cinema or watch a football match, the automatic failover will monitor the health of the product and will guarantee the continuous operation!
Author’s
 Serena Girardini, Workload Automation Test Technical Leader
Serena Girardini, Workload Automation Test Technical Leader
Serena Girardini is the System Verification Test Team leader for the Workload Automation product in distributed environments. She joined IBM in 2000 as a Tivoli Workload Scheduler developer and she was involved in the product relocation from San Jose Lab to Rome Lab during a short term assignement in San Jose (CA). For 14 years, Serena gained experience in Tivoli Workload Scheduler distributed product suite as developer, customer support engineer, tester and information developer. She covered for a long time the role of L3 fixpack releases Test Team Leader and in this period she was a facilitator during critical situations and upgrade scenarios at customer site. In her last 4 years at IBM she became IBM Cloud Resiliency and Chaos Engineering Test Team Leader. She joined HCL in April, 2019 as expert Tester for IBM Workload Automation product suite and she was recognized as Test Leader for the product porting to the most important Cloud offerings in the market. She has a math bachelor degree.
Linkedin: https://www.linkedin.com/in/serenagirardini/
 Filippo Sorino, Workload Automation Test Engineer
Filippo Sorino, Workload Automation Test Engineer
He joined HCL in September 2019 as Junior Software Developer starting to work as Tester for IBM Workload Automation product suite. He has a computer engineering bachelor degree.

Start a Conversation with Us
We’re here to help you find the right solutions and support you in achieving your business goals.





